HTTP、HTTPS等相关知识点整理
前言:什么是 HTTP?
-
优点
HTTP 最凸出的优点是「简单、灵活和易于扩展、应⽤⼴泛和跨平台」。- 简单
HTTP 基本的报⽂格式就是 header + body ,头部信息也是 key-value 简单⽂本的形式,易于理解,
降低了学习和使⽤的⻔槛。 - 灵活和易于扩展
HTTP协议⾥的各类请求⽅法、URI/URL、状态码、头字段等每个组成要求都没有被固定死,都允许开发⼈员⾃定义和扩充。同时 HTTP 由于是⼯作在应⽤层( OSI 第七层),则它下层可以随意变化。HTTPS 也就是在 HTTP 与 TCP 层之间增加了 SSL/TLS 安全传输层,HTTP/3 甚⾄把 TCP 层换成了基于 UDP 的 QUIC。 - 应⽤⼴泛和跨平台
互联⽹发展⾄今,HTTP 的应⽤范围⾮常的⼴泛,从台式机的浏览器到⼿机上的各种 APP,从看新闻、
刷贴吧到购物、理财、吃鸡,HTTP 的应⽤⽚地开花,同时天然具有跨平台的优越性。
- 简单
-
缺点
HTTP 协议⾥有优缺点⼀体的双刃剑,分别是「⽆状态、明⽂传输」,同时还有⼀⼤缺点「不安全」。 -
性能如何?
-
⻓连接
早期 HTTP/1.0 性能上的⼀个很⼤的问题,那就是每发起⼀个请求,都要新建⼀次 TCP 连接(三次握⼿),⽽且是串⾏请求,做了⽆谓的 TCP 连接建⽴和断开,增加了通信开销。
为了解决上述 TCP 连接问题,HTTP/1.1 提出了⻓连接的通信⽅式,也叫持久连接。这种⽅式的好处在于减少了 TCP 连接的 复建⽴和断开所造成的额外开销,减轻了服务器端的负载。
持久连接的特点是,只要任意⼀端没有明确提出断开连接,则保持 TCP 连接状态。 -
管道⽹络传输
HTTP/1.1 采⽤了⻓连接的⽅式,这使得管道(pipeline)⽹络传输成为了可能。
即可在同⼀个 TCP 连接⾥⾯,客户端可以发起多个请求,只要第⼀个请求发出去了,不必等其回来,就可以发第⼆个请求出去,可以减少整体的响应时间。 -
队头阻塞
「请求 - 应答」的模式加剧了 HTTP 的性能问题。
因为当顺序发送的请求序列中的⼀个请求因为某种原因被阻塞时,在后⾯排队的所有请求也⼀同被阻塞了,会招致客户端⼀直请求不到数据,这也就是「队头阻塞」。
-
1. HTTP 与 HTTPS 的区别
- HTTP 是超⽂本传输协议,信息是明⽂传输,存在安全⻛险的问题。HTTPS 则解决 HTTP 不安全的缺陷,在 TCP 和 HTTP ⽹络层之间加⼊了 SSL/TLS 安全协议,使得报⽂能够加密传输。
- HTTP 连接建⽴相对简单, TCP 三次握⼿之后便可进⾏ HTTP 的报⽂传输。⽽ HTTPS 在 TCP 三
次握⼿之后,还需进⾏ SSL/TLS 的握⼿过程,才可进⼊加密报⽂传输。 - HTTP 的端⼝号是 80,HTTPS 的端⼝号是 443。
- HTTPS 协议需要向 CA(证书权威机构)申请数字证书,来保证服务器的身份是可信的。
2. HTTP/1.1、HTTP/2、HTTP/3 演变
-
HTTP/1.1
- 相⽐ HTTP/1.0 性能上的改进:
使⽤ TCP ⻓连接的⽅式改善了 HTTP/1.0 短连接造成的性能开销。
⽀持管道(pipeline)⽹络传输,只要第⼀个请求发出去了,不必等其回来,就可以发第⼆个请求出去,可以减少整体的响应时间 - 性能瓶颈:
- 请求 / 响应头部(Header)未经压缩就发送,⾸部信息越多延迟越⼤。只能压缩 Body 的部分;
- 发送冗⻓的⾸部。每次互相发送相同的⾸部造成的浪费较多;
- 服务器是按请求的顺序响应的,如果服务器响应慢,会招致客户端⼀直请求不到数据,也就是队头阻塞;
- 没有请求优先级控制;
- 请求只能从客户端开始,服务器只能被动响应。
- 相⽐ HTTP/1.0 性能上的改进:
-
HTTP/2
HTTP/2 协议是基于 HTTPS 的,所以 HTTP/2 的安全性也是有保障的。- 相⽐ HTTP/1.1 性能上的改进:
- 头部压缩:HTTP/2 会压缩头(Header)如果你同时发出多个请求,他们的头是⼀样的或是相似的,那么,协议会帮你消除重复的部分。(这就是所谓的 HPACK 算法)
- ⼆进制格式:HTTP/2 不再像 HTTP/1.1 ⾥的纯⽂本形式的报⽂,⽽是全⾯采⽤了⼆进制格式,头信息和数据体都是⼆进制,并且统称为帧(frame):头信息帧和数据帧。增加了数据传输的效率。
- 数据流:HTTP/2 的数据包不是按顺序发送的,同⼀个连接⾥⾯连续的数据包,可能属于不同的回应。因此,必须要对数据包做标记,指出它属于哪个回应。每个请求或回应的所有数据包,称为⼀个数据流( Stream )。每个数据流都标记着⼀个独⼀⽆⼆的编号,其中规定客户端发出的数据流编号为奇数, 服务器发出的数据流编号为偶数。客户端还可以指定数据流的优先级。优先级⾼的请求,服务器就先响应该请求。
- 多路复⽤:HTTP/2 是可以在⼀个连接中并发多个请求或回应,⽽不⽤按照顺序⼀⼀对应。移除了 HTTP/1.1 中的串⾏请求,不需要排队等待,也就不会再出现「队头阻塞」问题,降低了延迟,⼤幅度提⾼了连接的利⽤率。
- 服务器推送:HTTP/2 还在⼀定程度上改善了传统的「请求 - 应答」⼯作模式,服务不再是被动地响应,也可以主动向客户端发送消息。例如浏览器刚请求 HTML 的时候,就提前把可能会⽤到的 JS、CSS ⽂件等静态资源主动发给客户端,减少延时的等待,也就是服务器推送(Server Push,也叫 Cache Push)。
- 缺陷
HTTP/2 主要的问题在于,多个 HTTP 请求在复⽤⼀个 TCP 连接,下层的 TCP 协议是不知道有多少个 HTTP 请求的。所以⼀旦发⽣了丢包现象,就会触发 TCP 的重传机制,这样在⼀个 TCP 连接中的所有的 HTTP 请求都必须等待这个丢了的包被重传回来
- 相⽐ HTTP/1.1 性能上的改进:
-
HTTP/3
HTTP/1.1 中的管道( pipeline)传输中如果有⼀个请求阻塞了,那么队列后请求也统统被阻塞住了
HTTP/2 多个请求复⽤⼀个TCP连接,⼀旦发⽣丢包,就会阻塞住所有的 HTTP 请求。
这都是基于 TCP 传输层的问题,所以 HTTP/3 把 HTTP 下层的 TCP 协议改成了 UDP!
3. TCP 和 UDP 区别
- 连接
- TCP 是面向连接的传输协议,传输数据前先要建立连接
- UDP 不需要连接,即刻传输数据
- 服务对象
- TCP 是一对一的两点服务,即一条连接只有两个端点
- UDP 支持一对一,一对多,多对多的交互通信
- 可靠性
- TCP 是可靠交付数据的,数据可以无差错、不丢失、不重复、按需到达
- UDP 是尽最大努力交付,不保证可靠交付数据
- 拥塞控制、流量控制
- TCP 有拥塞控制和流量控制机制,保证数据传输的安全性
- UDP 则没有,即使网络非常拥堵,也不会影响 UDP 的发送速率
- 首部开销
- TCP 首部长度较长,会有一定的开销,首部在没有使用【选项】字段时是 20 个字节,如果使用了【选项】字段则会变长的
- UDO 首部只有 8 个字节,并且是固定不变的,开销较小
- 传输方式
- TCP 是流式传输,没有边界,但保证顺序和可靠
- UDP 是一个包一个包的发送,是有边界的,但可能会丢包和乱序
- 分片不同
- TCP 的数据大小如果大于 MSS 大小,则会在 传输层 进行分片,目标主机收到后,也同样在传输层组装 TCP 数据包,如果中途丢失了一个分片,只需要传输丢失的这个分片。
- UDP 的数据大小如果大于 MTU 大小,则会在 IP 层进行分片,目标主机收到后,在 IP 层组装完数据,接着再传给传输层,但是如果中途丢了一个分片,则就需要重传所有的数据包,这样传输效率非常差,所以通常 UDP 的报文应小于 MTU。
-
TCP 和 UDP 的应用场景:
由于 TCP 是面向连接的,能保证数据的可靠交付,因此经常用于:
1. FTP 文件传输
2. HTTP / HTTPS由于 UDP 是面向无连接的,它可以随时发送数据,再加上 UDP 本身的处理既简单又高效,因此经常用于:
1. 包总量较少的通信,如 DNS、SNMP 等
2. 视频、音频等多媒体通信
3. 广播通信
3. TCP 3次握手
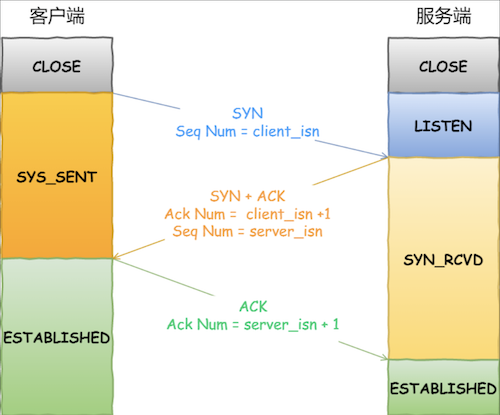
- ⼀开始,客户端和服务端都处于 CLOSED 状态。先是服务端主动监听某个端⼝,处于 LISTEN 状态。
- 然后客户端主动发起连接 SYN ,之后处于 SYN-SENT 状态。
- 服务端收到发起的连接,返回 SYN ,并且 ACK 客户端的 SYN ,之后处于 SYN-RCVD 状态。
- 客户端收到服务端发送的 SYN 和 ACK 之后,发送 ACK 的 ACK ,之后处于 ESTABLISHED 状态,因为它⼀发⼀收成功了。
- 服务端收到 ACK 的 ACK 之后,处于 ESTABLISHED 状态,因为它也⼀发⼀收了。
3.1 为什么是三次握⼿?不是两次、四次?
-
可以阻⽌重复历史连接的初始化(主要原因)
客户端连续发送多次 SYN 建⽴连接的报⽂,在⽹络拥堵情况下:- ⼀个「旧 SYN 报⽂」⽐「最新的 SYN 」 报⽂早到达了服务端;
- 那么此时服务端就会回⼀个 SYN + ACK 报⽂给客户端;
- 客户端收到后可以根据⾃身的上下⽂,判断这是⼀个历史连接(序列号过期或超时),那么客户端
- 就会发送 RST 报⽂给服务端,表示中⽌这⼀次连接。
- 如果是两次握⼿连接,就不能判断当前连接是否是历史连接,三次握⼿则可以在客户端(发送⽅)准备
- 发送第三次报⽂时,客户端因有⾜够的上下⽂来判断当前连接是否是历史连接:
- 如果是历史连接(序列号过期或超时),则第三次握⼿发送的报⽂是 RST 报⽂,以此中⽌历史连接;
- 如果不是历史连接,则第三次发送的报⽂是 ACK 报⽂,通信双⽅就会成功建⽴连接;
所以,TCP 使⽤三次握⼿建⽴连接的最主要原因是防⽌历史连接初始化了连接。
-
可以同步双⽅的初始序列号
TCP 协议的通信双⽅, 都必须维护⼀个「序列号」, 序列号是可靠传输的⼀个关键因素,它的作⽤:- 接收⽅可以去除 复的数据;
- 接收⽅可以根据数据包的序列号按序接收;
- 可以标识发送出去的数据包中, 哪些是已经被对⽅收到的;
-
可以避免资源浪费
如果只有「两次握⼿」,当客户端的 SYN 请求连接在⽹络中阻塞,客户端没有接收到 ACK 报⽂,就会重新发送 SYN ,由于没有第三次握⼿,服务器不清楚客户端是否收到了⾃⼰发送的建⽴连接的ACK 确认信号,所以每收到⼀个 SYN 就只能先主动建⽴⼀个连接,这会造成什么情况呢?
如果客户端的 SYN 阻塞了, 复发送多次 SYN 报⽂,那么服务器在收到请求后就会建⽴多个冗余的⽆效链接,造成不必要的资源浪费。 -
总结:
TCP 建⽴连接时,通过三次握⼿能防⽌历史连接的建⽴,能减少双⽅不必要的资源开销,能帮助双⽅同步初始化序列号。序列号能够保证数据包不重复、不丢弃和按序传输。 -
不使⽤「两次握⼿」和「四次握⼿」的原因:
- [两次握⼿]:⽆法防⽌历史连接的建⽴,会造成双⽅资源的浪费,也⽆法可靠的同步双⽅序列号;
- [四次握⼿]:三次握⼿就已经理论上最少可靠连接建⽴,所以不需要使⽤更多的通信次数。
4. TCP 4次挥手
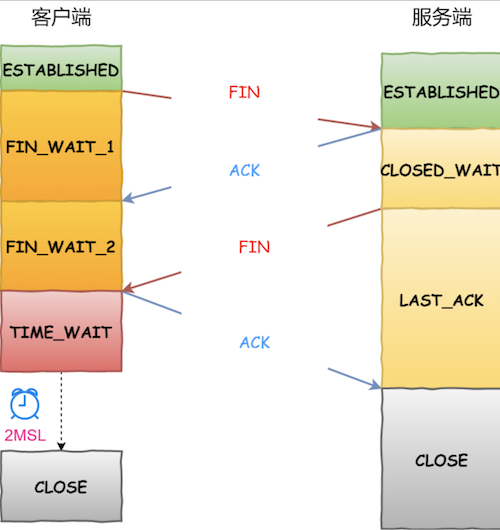
- 客户端打算关闭连接,此时会发送⼀个 TCP ⾸部 FIN 标志位被置为 1 的报⽂,也即 FIN 报⽂,之后客户端进⼊ FIN_WAIT_1 状态。
- 服务端收到该报⽂后,就向客户端发送 ACK 应答报⽂,接着服务端进⼊ CLOSED_WAIT 状态。
- 客户端收到服务端的 ACK 应答报⽂后,之后进⼊ FIN_WAIT_2 状态。
- 等待服务端处理完数据后,也向客户端发送 FIN 报⽂,之后服务端进⼊ LAST_ACK 状态。
- 客户端收到服务端的 FIN 报⽂后,回⼀个 ACK 应答报⽂,之后进⼊ TIME_WAIT 状态
- 服务器收到了 ACK 应答报⽂后,就进⼊了 CLOSED 状态,⾄此服务端已经完成连接的关闭。
- 客户端在经过 2MSL ⼀段时间后,⾃动进⼊ CLOSED 状态,⾄此客户端也完成连接的关闭。
可以看到,每个⽅向都需要⼀个 FIN 和⼀个 ACK,因此通常被称为四次挥⼿。
4.1 为什么四次挥手?TIME_WAIT == 2MSL?
-
为什么4次挥手
- 关闭连接时,客户端向服务端发送 FIN 时,仅仅表示客户端不再发送数据了但是还能接收数据。
- 服务器收到客户端的 FIN 报⽂时,先回⼀个 ACK 应答报⽂,⽽服务端可能还有数据需要处理和发送,等服务端不再发送数据时,才发送 FIN 报⽂给客户端来表示同意现在关闭连接。
从上⾯过程可知,服务端通常需要等待完成数据的发送和处理,所以服务端的 ACK 和 FIN ⼀般都会分开发送,从⽽⽐三次握⼿导致多了⼀次。
-
为什么 TIME_WAIT 等待的时间是 2MSL?
TIME_WAIT 等待 2 倍的 MSL,⽐较合理的解释是: ⽹络中可能存在来⾃发送⽅的数据包,当这些发送⽅的数据包被接收⽅处理后⼜会向对⽅发送响应,所以⼀来⼀回需要等待 2 倍的时间。在 Linux 系统⾥ 2MS 默认是 60 秒,那么⼀个 MSL 也就是 30 秒。Linux 系统停留在 TIME_WAIT 的时间为固定的 60 秒。
5. 键入网址后都发生了什么?
- 解析 URL,生成 HTTP 的请求信息
- 真实地址查询 -- DNS ( 【本地 - 根 - 顶级域 - 权威】 DNS服务器 )
- 协议栈
通过 DNS 获取到 IP 后,就可以把 HTTP 的传输⼯作交给操作系统中的协议栈。
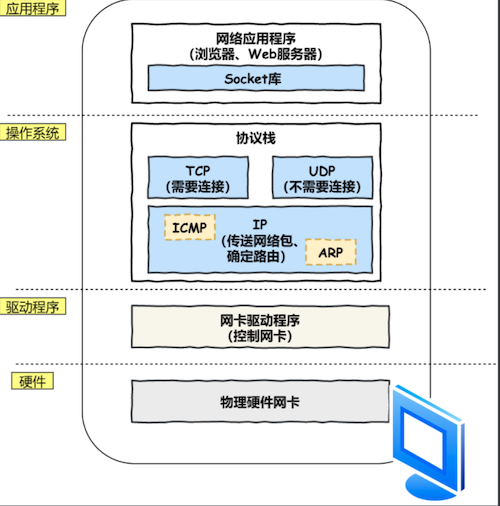
- 3.1 可靠传输:TCP
协议栈的上半部分有两块,分别是负责收发数据的 TCP 和 UDP 协议,它们两会接受应⽤层的委托执⾏收发数据的操作。 - 3.2 远程定位:IP
协议栈的下⾯⼀半是⽤ IP 协议控制⽹络包收发操作,在互联⽹上传数据时,数据会被切分成⼀块块的⽹络包,⽽将⽹络包发送给对⽅的操作就是由 IP 负责的。此外 IP 中还包括 ICMP(error信息) 协议和 ARP(IP - MAC 映射) 协议。 - 3.3 两点传输:MAC
⽣成了 IP 头部之后,接下来⽹络包还需要在 IP 头部的前⾯加上 MAC 头部。MAC 头部是以太⽹使⽤的头部,它包含了接收⽅和发送⽅的 MAC 地址等信息。
- 3.1 可靠传输:TCP
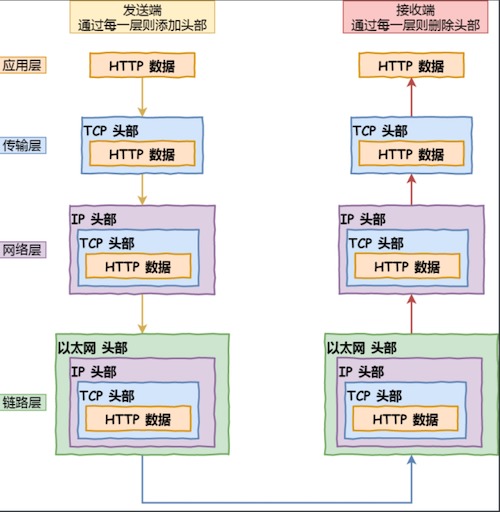
- 出口 - 网卡
我们需要将数字信息转换为电信号,才能在⽹线上传输,负责执⾏这⼀操作的是⽹卡,要控制⽹卡还需要靠⽹卡驱动程序。 - 送别者 - 交换机
交换机的设计是将⽹络包原样转发到⽬的地。交换机⼯作在MAC 层,也称为⼆层⽹络设备。 - 出境⼤⻔ - 路由器
⽹络包经过交换机之后,现在到达了路由器,并在此被转发到下⼀个路由器或⽬标设备。 - 互相扒⽪ - 服务器 与 客户端
数据包抵达服务器后,服务器开逐层解包
6. POST / GET 区别
- Get ⽅法的含义是请求从服务器获取资源; ⽽ POST ⽅法则是相反操作,它向 URI 指定的资源提交数据,数据就放在报⽂的 body ⾥。
- GET: 是安全且幂等的,因为它是「只读」操作,⽆论操作多少次,服务器上的数据
都是安全的,且每次的结果都是相同的。
POST: 因为是「新增或提交数据」的操作,会修改服务器上的资源,所以是不安全的,且多次提交数据就会创建多个资源,所以不是幂等的。
7. 常见的状态码

8. 常用字段
- Host
客户端发送请求时,⽤来指定服务器的域名。【www.A.com】有了 Host 字段,就可以将请求发往「同⼀台」服务器上的不同⽹站。 - Content-Length
服务器在返回数据时,会有 Content-Length 字段,表明本次回应的数据⻓度。【Content-Length: 1000】 - Connection
Connection 字段最常⽤于客户端要求服务器使⽤ TCP 持久连接,以便其他请求复⽤。【Connection: keep-alive】 - Content-Type
Content-Type: ⽤于服务器回应时,告诉客户端,本次数据是什么格式。【Content-Type: text/html; charset=utf-8】
Accept: 客户端请求的时候,可以使⽤ Accept 字段声明⾃⼰可以接受哪些数据格式。【Accept: ※/※】 - Content-Encoding
Content-Encoding: 说明数据的压缩⽅法。表示服务器返回的数据使⽤了什么压缩格式 。【Content-Encoding: gzip】
Accept-Encoding:客户端在请求时,⽤ Accept-Encoding 字段说明⾃⼰可以接受哪些压缩⽅法。【Accept-Encoding: gzip, deflate】